


In previous CIO.com articles, we talked about three of the five capabilities needed to turn data into insight. The fourth key capability is to have “data-centric processes.”
What we mean by this is twofold:
- There are processes embedded into the organization that are focused on data and data management and optimization.
- There is a recognition that data is an input and a valuable output of other processes in the organization, and these inputs and outputs are understood and retained to extend data understanding in the organization.
Many articles have been written about data-management-specific processes, including the two previous installments in our CIO.com series, Ensuring the Quality of "Fit for Purpose" Data and Mastering and Managing Data Understanding. In this installment, we cover processes that already exist within an organization. We look at the role of data and discuss how to make the related processes more data-centric. We also break down the ways data-centric processes can have the most impact on an organization in:
- Project design and definition
- Project implementation
- Operational execution
Project design and definition
As data management projects or initiatives are identified and launched, there is an opportunity to leverage data understanding to improve the project planning process. According to the Project Management Institute's Project Management Book of Knowledge, the typical project management life cycle has these five phases:
Initiate > plan > execute > monitor and control > close
In the Initiate and Plan steps, you should define the project’s vision and scope as well as identify stakeholders. Data is critical to the definition of scope, because there will be data used in the project and there may be data created as part of the project. The way data is used, created or even acquired will impact the cost of the project — potentially the risks identified in it, of course, the impact of the project on other people, processes and technology across your organization. Without a clear understanding of your data (as we discussed in Mastering and Managing Data Understanding), the scope may not be properly defined and this could result in significant budget and resource overruns.
The data that is used in a project may also be used by others within the organization, so a full understanding of how data flows across the organization will help to ensure the correct stakeholders are identified. In the previously mentioned article, we talked about the creation of a data inventory or data landscape. This artifact is critical to the ability to know who else in the organization touches the data, and, therefore, should inform the project initiation and stakeholder identification phase.
Stakeholders should represent different functions and processes that are critical to the success of the project, so knowing who “owns” or uses the data ensures you have the appropriate decision-makers as part of the team. Of course, if you have an established data governance organization, they would be central to this process to triage the impact of the project on the rest of the organization.
In this way, putting a data-centric lens on the project planning process through design and definition will ensure you have a full picture of the costs, risks, resource implications and benefits of the project before a significant amount of money is invested.
Project implementation
During the project’s execution phase, there are additional ways to optimize data as you implement new technologies or processes in an organization. A data-centric implementation approach focuses on addressing the data requirements, ensuring data consistency across existing models and metadata, and extending the data understanding as part of the project process.
Data-centric development projects, such as master data management and business intelligence and analytics projects, have risks that are different from traditional process-centric development processes.
Unfortunately, process-centric methodologies, mainly systems development life cycle (SDLC, a.k.a. waterfall) and agile, are used in these projects and largely miss the data-centric needs. For instance, the starting point of a data-centric project is existing production data, as opposed to a process that needs automation, which is usual in process-centric projects. It is highly unlikely the business users will understand this data sufficiently to provide detailed requirements. They may not even know where to find the data or if it even exists.
As the source data is better understood, the users become better able to provide requirements, but this requires cycles of iteration. However, such cycles are not inherent in waterfall or agile. Where the traditional methodologies are used, what often happens is that when the users see outputs — say at user acceptance testing — they realize these are not correct or what they want. By this time, unfortunately, the project is too far advanced to accommodate changes and the developers blame the users for not being clear about their requirements.
Data-centric Development Life Cycle
At First San Francisco Partners, we created a detailed project methodology for data-centric development projects that we call the Data-Centric Development Life Cycle (DCLC). This recognizes both the risks involved in and the specific tasks needed for data-centric projects.
A methodology like DCLC is very much needed for data-centric projects. Without it, the risks such as the users being unfamiliar with the source data, are not mitigated. Additionally, tasks that are specific to data-centric projects are identified. This means they can be put into project plans as line items and have resources with the correct skill sets assigned to them. If this is not done, then the tasks are either omitted or done informally as part of some other activity that is scheduled in the project plan. The project plan then becomes unrealistic and the data-centric activities, to the extent they are performed at all, typically get cut off before they are completed by a date in the project plan that is somewhat arbitrarily set. An approach like the DCLC is much more likely to produce success with data-centric projects and contribute to the overall data-centricity that modern enterprises need to unlock the value in their data assets.
Operational Execution
Many processes within organizations create or change data, so it is important to view and understand them via a data-centric lens to ensure the key inputs and outputs of the process (the data) is optimized — not just the time it takes to execute on that process.
Reviewing data-related processes gives you an opportunity to ensure that data is created according to established quality standards and guidelines — rather than just as a formality that needs to be completed by a certain date or time. By doing this, you will see significantly different results in the data that is then used by other parts of the organization for planning and analysis and for customer engagement.
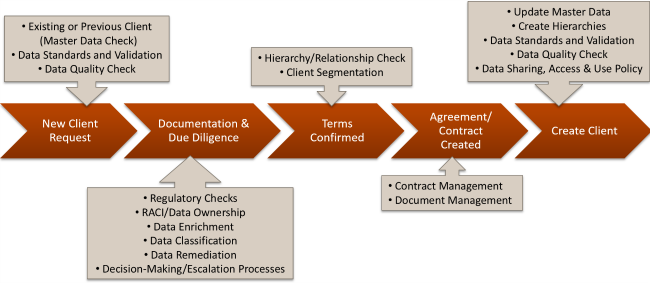
Here is a typical client on-boarding process example for a financial institution. I chose this example because most of us can relate to opening a bank account, acquiring a home mortgage or establishing a line of credit. It is also a great example of a complex process with different points in which the data is checked and validated across both internal and external sources.
The client on-boarding process is indicated as a series of chevrons in the middle of the graphic. Pointing to each step in the chevron are those data artifacts or processes that could be involved to ensure that the data is created and validated in a way that increases client understanding within the financial institution.
For example, in the first step where a new client request comes into an organization (i.e., a new loan application), there is an opportunity to check this information against existing data stores to determine if they are or have ever been a customer. Understanding whether they are or were a customer by referencing a master data repository would help with the determination of credit worthiness and, therefore, the potential value or cost of that transaction. Also, creating the initial record in a way that adheres to the data quality standards ensures that information can smoothly flow through the information supply chain without further quality adjustments.
In the second step of the process where additional documentation is gathered and further client due diligence is performed, there are different artifacts that can be leveraged. For example, that new client record can be checked against regulatory lists and databases to determine whether that individual is restricted in any way. Maybe the data is enriched with purchased information to further understand demographics and credit worthiness. And, as a result, there may be data remediation that occurs to update the record for full accuracy. All of this can leverage existing data governance and data management processes around data ownership, accountability and decision-making.
Additional steps in the above process follow in a similar manner, where key inputs and outputs are reviewed and optimized.
The value of data-centric processes
Data is both a critical input to the key processes in an organization, as well as a valuable output. Every day in your organization, there is an opportunity to improve data with embedded processes that are data-centric. Then, as data is managed as an asset along the information supply chain, the value produced by derived insights will be better understood, more trusted and delivered in the timeliest way.
— Originally published on our CIO.com channel “Turning Data Into Insight” December 14, 2016
Array

