


Data is abstract. We can't touch it or feel it, so we form mental concepts of it. Similarly, we find it difficult to pin down data quality with its conflicting definitions and terminology. Yet, there are fundamental concepts of data quality that information management professionals should rely on.
Data Quality's Manufacturing Roots
Data quality is difficult to define, in part, because its definitions aren't typically oriented to operationalization. Also, there are deeply rooted data quality definitions that date back a half-century.
First, let's look at the data quality definition from engineer and management consultant Joseph M. Juran:
... data to be of high quality if they are fit for their intended uses in operations, decision-making and planning.1
Juran was well-known in the manufacturing industry for his quality perspectives. (His data quality control handbook, which I have, is about the size of a cinder block.) Juran is where we get the idea that data should be fit for use and data quality is fitness for use. But there’s a problem with this definition. Juran was talking about the data you get when, for example, you measure the manufacturing defects of items coming off a conveyor belt. He wasn’t talking about data in the same way we talk about it today.
Larry P. English, another early pioneer of information quality management, offered this definition2:
(1) Consistently meeting all knowledge work and end-customer expectations in all quality characteristics of the information products and services required to accomplish the enterprise mission (internal knowledge worker) or personal objectives (end customer).
(2) The degree to which information consistently meets the requirements and expectations of all knowledge workers who require it to perform their processes.
But English's definition, like Juran's, is also dependent on how the data is used.

How Data Quality is Like Coffee Quality
Let's turn our attention to coffee, for a moment, where quality is judged on the presence of its defects. If you visit the USDA website, you’ll find that for a hundred pounds of coffee it's likely to have a certain number of sticks, stones and other debris in it. Theses defects are the objective, negative qualities of the coffee. Another quality judgement is how people perceive the quality of coffee: one person likes dark roast, while the other likes medium roast coffee.
Turning back to data, a quality measure is the usability of data for its given requirements and how well it fits a need — and these are contextual, positive qualities.
Move From Manufacturing to Modern Definitions
Along with Juran, we have the engineer, statistician and management consultant W. Edwards Deming of Six Sigma fame. Deming, who was once the head of the U.S. Census Bureau, instituted the manufacturing quality revolution in Japan after World War II. (Deming was inspired by engineer and statistician Walter A. Shewhart, another quality expert and true genius and someone who is not as well recognized and should be.)
These manufacturing-based definitions took hold for data, with people espousing them for years. But it’s time to rethink these definitions, because data is different.
The "Truth" About Data
When we ask, “What is data?”, we can look to Aristotle’s Correspondence Theory of Truth, which is a connection between representation and reality. That is what truth is, according to Aristotle. He said:
“To say of what is that it is not, or of what is not that it is, is false — while to say of what is that it is, and of what is not that it is not, is true."
Put more simply, data represents something else. The extent to which it accurately represents something else is a measure of its quality.
Data Represents a Thing, Event or Concept
Philosopher, logician, mathematician and scientist Charles Sanders Peirce — probably the greatest mind ever produced in America — is known as the father of pragmatism. His work is what gives us graph databases today and a lot of symbolic logic. He devised a schema that illustrates there is a thing, event or a concept which is represented by data — and these must be understood by an interpreter. An interpreter is any mind or machine that uses the data and needs to understand it. Data is the stored representation of a fact. And the thing, event, or concept is what’s out there in the real world.
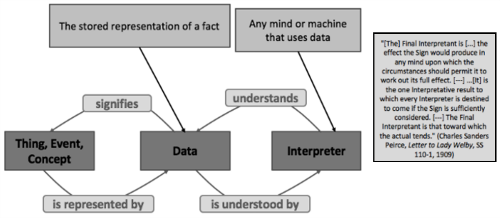
Philosopher, logician, mathematician and scientist Charles Sanders Peirce is known as the father of pragmatism. His work is what gives us graph databases today and a lot of symbolic logic.
For data to represent what it purports to represent, you must know what it’s supposed to be representing. That’s metadata — and what’s purported has to match the actual data values. Of course, the extent to which data satisfies a specific requirement is context-dependent. For example, in my former life I took data out of loan processing systems, which served very well in those systems for the business’s use cases. Then I attempted to use the data for securitization purposes (for issuing bonds), and it was of poor quality in that context.
Data is Objective and Contextual
With data quality, there’s an objective side and a contextual side with positive quality aspects. Data quality is judged by how well it accurately represents something and how useful it is to the interpreters of that data or the end users.
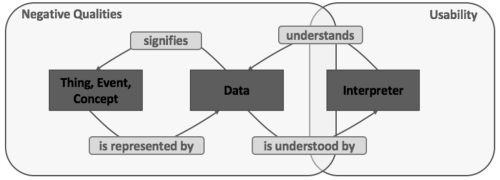
With data quality, there’s an objective side and a contextual side with positive quality aspects. There are negative quality problems, as well, including the usability (the positive problems).
What we see as we look at the above schematic a bit closer is that these two aspects of data quality need governance. They need to be understood, governed and managed. You have the negative quality problems, and then you have the usability (the positive problems). Traditionally, we focused on data quality dimensions, like accuracy and timeliness, which are actually opposite of the negative qualities. But these usability attributes are typically not dealt with very well.
If we turn to the areas of analytics and data science, we often hear discussions that aren’t focused on the negative qualities of data. For example, a particular data set doesn’t work well for an area’s analytics needs. The data might be fully accurate and timely, but it doesn’t fit their use case and it will be described as a data quality issue. This is why it’s important to understand the distinctions in data quality and determine what is core to the problem.
Data's Fit For Purpose is Subjective
We must not blame quality on the improper choice of data for a process. For example, if an analyst has metadata available to him and he doesn't do a good job with due diligence — i.e., he makes assumptions about the data that produce bad results in his analytics — then it’s not the data’s fault.
Deming said there’s no true value of anything — there’s just an estimate we can get close to. Our best estimate of the speed of light is still an estimate and not a true value. But thinking of data like scientific observations or data points to measure is not helpful.
By contrast, Peirce observed that the balance in a bank account is known exactly. It has infinitely greater accuracy than any measurement in the physical sciences. As it is with much of the data we curate in books and records, this is the reality. There is no variation, and we’re not making a measurement or estimate.
Data Quality Management
The scope of data quality management is another problem in addition to the definitional issues. Often when our industry talks about data quality management, what they mean are data quality detection, data issue management and data change management.
Data quality detection is the detection of data issues, and that typically involves our Information Technology partner. This is because IT creates the processes that manage the data, and they are in a position to find out if those processes lead to data defects. For example, if we get addresses or names wrong, this should be detectable by some form of automated instrumentation.
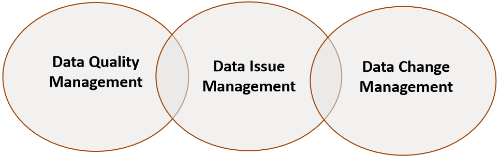
Data quality management, data issue management and data change management are important components of any discussion about data quality.
Data Issue Management
Data issue management is where we determine the resolution options. Here, our partner isn’t usually IT — it’s the business side. The business knows what the data is used for and the business processes that utilize IT’s information management infrastructure.
Remediating data is one possibility. Changing root causes is another. Sometimes, the data problem isn’t an issue – it’s a false positive (something that’s reported as an issue, but really isn’t).
Data Change Management
Data change management is the application of the corrective actions to data and related processes — and here it’s a mixture of the business and IT. If it’s zapping data in Production to correct it, the data governance area has a strong interest in this and will want to see there’s a rollback plan — as well as ensure the data is backed up before that happens. Also of interest: audit logs; ensuring scripts that are applied are preserved (regulators may want to look at them, too); and the metadata that goes with the data.
Assessing the impact of the change is even more important. Some companies have data review boards or data steward networks set up to do this before the change is implemented.
Data Quality Dimensions
Next, let’s move on to data quality dimensions — accuracy, timeliness, redundancy, etc. Rather than treating these as abstractions for which there’s a definition and an associated metric, we must make these more definable. Each of the dimensions are something we need to measure, and there’s a tremendous number of arguments about how to define them.
Here is the Enterprise Data Management Council’s definition of data accuracy:
“Referring to the correctness or incorrectness of data (i.e. degree to which data is a representation of the context as it was published; how it reconciles to original or third-party source.”
This definition could be improved, as it’s talking about correctness and reconciliation to a source. But, for other people, that’s consistency.
The International Association for Information and Data Quality has its own definition. In fact, it has three:
ACCURACY: degree of conformity of a measure to a standard or true value. Level of precision or detail.
ACCURACY TO REALITY: a characteristic of information quality measuring the degree to which a data value (or set of data values) correctly represents the attributes of the real-world object or event. (Larry English)
ACCURACY TO SURROGATE SOURCE: a measure of the degree to which data agrees with an original, acknowledged authoritative source of data about a real-world object or event, such as a form, document or unaltered electronic data received from outside the organization. See also Accuracy. (Larry English)
This states that accuracy is generally a degree of conformity or measure to a standard or true value – i.e., the level of precision or detail. But the level of precision is something different from accuracy. And what does conformity to a standard mean? Accuracy to reality is a comparison to the real world. (That is similar to Aristotle’s Theory of Truth.) Accuracy to surrogate source is comparing the source to a target. (That speaks to “consistency.”)
What we’re seeing with these definitions is that they are somewhat difficult to understand and to put to use.
To Define Data Quality, Begin With Questions
If we look closely at data dimensions, we see they provoke questions we could ask about the data. There are different types of analytical techniques that we would bring to bear to do this.
Here are examples of questions that are specific and more oriented to real-world data quality scenarios — and more worth our time to focus on vs. attempting an academic exercise around what is timely or accurate data.
It's Up to Us to Define Data Quality
Through the years, data quality has been difficult to deal with because it inherited its meaning from manufacturing and services. Data quality dimensions have been flawed, too, and that is why formulating specific questions to derive metrics is valuable — even though answering those questions will require a wide range of different approaches.
Information management professionals should lead the way to forge a new path to define data quality, rather than adopt dated ideas about quality outside of data management and data governance. It won’t be easy, but it’s a worthwhile effort we must do ourselves.
1 Juran, Joseph M. and A. Blanton Godfrey, Juran's Quality Handbook, Fifth Edition, p 2.2, McGraw-Hill, 1999
2 Larry English, as quoted in International Association for Information Data Quality Glossary.
Article contributed by Malcolm Chisholm. He brings more than 25 years’ experience in data management, having worked in a variety of sectors including finance, insurance, manufacturing, government, defense and intelligence, pharmaceuticals and retail. Malcolm's deep experience spans specializations in data governance, master/reference data management, metadata engineering, business rules management/execution, data architecture and design, and the organization of enterprise information management.
Array

